


Le principali ricerche indicano che circa il 50% delle grandi aziende dispone di un parco applicativo sul Cloud, sicuramente un dato che testimonia l’importanza rivestita da queste sorgenti esterne. Di conseguenza, le organizzazioni necessitano di strumenti altrettanto moderni per elaborare e integrare questi dati rapidamente.
Ma a quale approccio possiamo fare riferimento? E nell’era dei Big Data quali strumenti permettono di gestire il loro volume, la loro varietà e dinamicità? In questo articolo proveremo a fare un po’ di chiarezza, andando a mettere a confronto due fondamentali approcci concettuali alla Data Integration: ETL e ELT.
Ma prima soffermiamoci su cosa si intende per Data Integration. La Data Integration è il processo di trasformazione dei dati grezzi in modelli analitici, che possono servire a scopi aziendali e aiutare a guidare le decisioni strategiche.

Poiché la quantità di dati generati continua a crescere in modo esponenziale, le organizzazioni hanno bisogno di modi migliori per integrare questi dati. Una visione più unificata e coerente permette alle aziende un lavoro più produttivo, così come un aumento della loro competitività sul mercato, facendosi guidare dai dati. Con un’efficace Data Integration, si possono estrarre dati da una varietà di fonti, inclusi database on premises, applicazioni in Cloud, dati in tempo reale e flussi di dati online.
Cos’è allora l’ETL?
L’approccio tradizionale all’integrazione dei dati, Extract-Transform-Load (ETL), risale agli anni ’70 ed è così onnipresente che il termine ETL è spesso usato in modo intercambiabile con il concetto di Data Integration. In ETL, le pipeline prevede l’estrazione dei dati dalle origini, la trasformazione di questi in modelli dati che gli analisti possono convertire in report e dashboard, ed infine il caricamento di queste informazioni in un data warehouse.

Le trasformazioni dei dati in genere aggregano o riepilogano i dati, riducendone il volume complessivo. Quando l’ETL è stato ideato per la prima volta, la maggior parte delle organizzazioni operava sotto vincoli tecnologici molto stringenti, in cui archiviazione, calcolo e larghezza di banda erano estremamente scarsi. Quindi trasformando prima del caricamento, l’ETL permette di limitare il volume dati che viene archiviato.
L’utilizzo di strumenti ETL per la Data Integration comporta affrontare quindi le seguenti sfide:
- Manutenzione costante: poiché la pipeline di dati estrae e trasforma i dati, nel momento in cui gli schemi a monte cambiano o i modelli di dati a valle devono essere modificati, la pipeline si interrompe ed è necessaria una revisione spesso estesa.
- Personalizzazione e complessità: le pipeline di dati non solo estraggono i dati, ma eseguono trasformazioni sofisticate su misura per le esigenze di analisi specifiche degli utenti finali. Ciò significa che bisognerà generare grandi quantità di codice personalizzato.
- Elevata intensità di manodopera e costo: poiché il sistema viene eseguito su una base di codice personalizzato, è necessario un team di ingegneri di dati dedicati per la creazione e la manutenzione.
Queste sfide derivano dal compromesso chiave effettuato nell’ambito dell’ETL, che consiste nel conservare le risorse di calcolo e archiviazione a scapito del lavoro.
Cos’è l’ELT? Una moderna alternativa all’ETL
La capacità di archiviare i dati non trasformati nei data warehouse consente una nuova architettura di integrazione dei dati, Extract-Load-Transform (ELT), in cui i dati vengono caricati immediatamente in una destinazione al momento dell’estrazione e la fase di trasformazione viene spostata alla fine del flusso di lavoro.
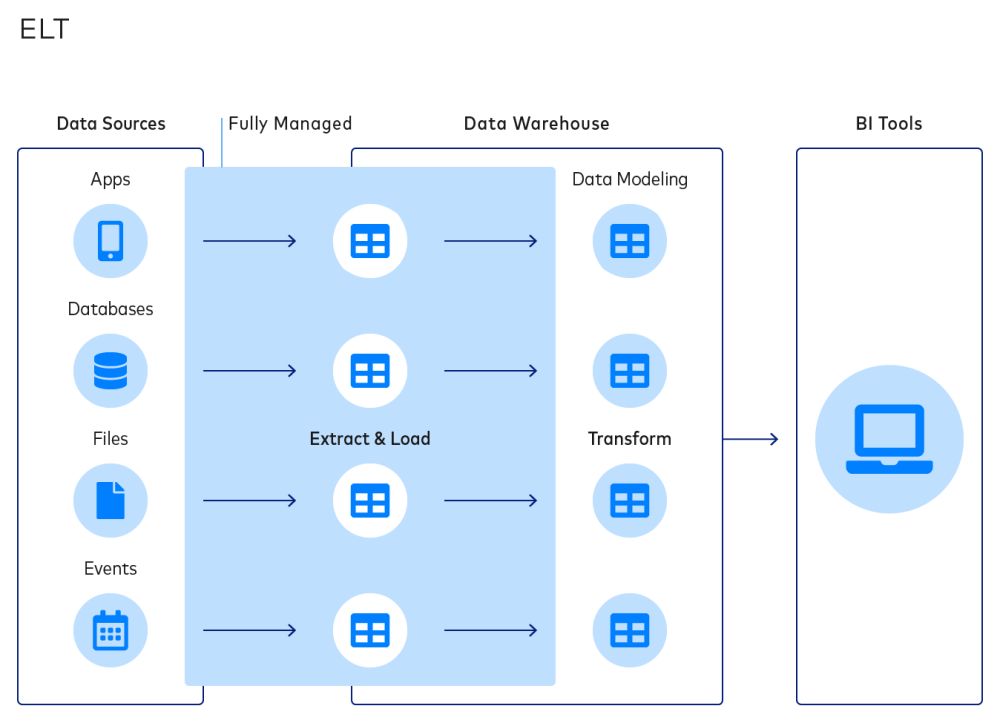
In ELT, l’estrazione e il caricamento dei dati sono indipendenti dalla trasformazione, in quanto sono a monte di essa. Sebbene il livello di trasformazione possa ancora non riuscire quando gli schemi a monte o i modelli di dati a valle cambiano, questi non impediranno il caricamento dei dati verso una destinazione.
Al contrario, anche se le trasformazioni vengono periodicamente riscritte dagli analisti, un’organizzazione può continuare a estrarre e caricare dati. Questi dati arrivano a destinazione con alterazioni minime e serviranno come fonte di verità completa e aggiornata. Inoltre, poiché le trasformazioni vengono eseguite all’interno dell’ambiente del data warehouse, non è più necessario scrivere trasformazioni utilizzando lunghi linguaggi di scripting come Python o creare orchestrazioni complesse tra origini dati disparate.
Principali differenze tra ETL ed ELT
La tabella seguente riassume in conclusione le differenze tra ETL ed ELT:
| ETL | ELT |
| Estrai, trasforma, carica | Estrai, carica, trasforma |
| Integra dati aggregati | Integra tutti i dati grezzi |
| Caricamento e trasformazione strettamente accoppiati | Caricamento e trasformazione disaccoppiati |
| Tempo più lungo per caricare i dati | Tempo più breve per caricare i dati |
| Gli errori di trasformazione interrompono la pipeline | Gli errori di trasformazione non interrompono la pipeline |
| Su misura | Standard |
| Costruzione e manutenzione costanti | Automatizzato |
| Conserva calcolo e archiviazione | Risparmia tempo e lavoro |
| Basato su cloud o on-premise | Quasi rigorosamente cloud-based |
Ci sono alcuni casi in cui l’ETL potrebbe essere ancora preferibile rispetto all’ELT. Questi includono specificatamente i casi in cui:
- I modelli di dati desiderati sono ben noti ed è improbabile che cambino rapidamente. Ciò è particolarmente vero quando un’organizzazione crea e gestisce anche sistemi che generano dati di origine.
- Esistono severi requisiti di sicurezza e conformità alle normative riguardanti i dati e non possono assolutamente essere archiviati in alcun luogo che potrebbe essere compromesso.
Con Fivetran realizza i vantaggi dell’ELT e dell’automazione
Un’organizzazione che combina l’automazione con l’ELT semplifica notevolmente il flusso di lavoro di integrazione dei dati. Una soluzione di Data Integration semplificata consente perciò ai Data Analyst di concentrarsi su progetti mission-critical invece di costruire e mantenere pipeline di dati.
Tra le soluzioni ottimali sicuramente non può mancare Fivetran, la tecnologia più veloce e affidabile per accedere ai tuoi dati senza interruzioni e senza implementazioni. Fivetran è un servizio di integrazione dati SaaS che consente di estrarre, caricare e trasformare dati provenienti da diversi ambienti. In parole povere, Fivetran sposta i tuoi dati da oltre 180 connettori verso una destinazione a tua scelta.

Fivetran rivede appunto il processo di spostamento dati verso un sistema di destinazione centralizzato passando da ETL a ELT. Questo approccio accelera il “time to value” assicurando alte prestazioni, per sfruttare appieno il potere informativo dei propri dati.
Per saperne di più, potresti guardare il nostro webinar su Fivetran, in cui presentiamo la partnership appena nata!
E se ancora qualcosa non ti è chiaro e vuoi qualche informazione in più, non esitare a scriverci su info@visualitics.it!